

PyTorch is a Python-based Machine Learning library with GPU support. It can be used as easily as NumPy and is built upon the famous Torch library. The main feature is that Neural Networks can be built dynamically making way for learning more advanced and complex AI tasks.
hen it comes to implementing Deep Learning models, there are ample Open Source frameworks available. One of the popular frameworks – Torch, started as a scientific computing library in Lua programming language, but with the integration of CUDA C (for GPU computing) and ML Libraries, it soon became a standard ML Framework. Deep Mind was using Torch7 before moving on to Google’s TensorFlow framework. Facebook is one of the major users and contributors for Torch.
One reason for Torch losing its popularity is because of learning LuaJIT. Although LuaJIT is the fastest JIT (Just-In-Time compiled language) and interfaces very well with C/C++, learning it is a significant bottleneck for newcomers and enthusiasts. But now, Facebook AI Research (FAIR) has released the PyTorch framework – A Python Wrapper for Torch. PyTorch aims to remove this bottleneck and is packed with lots of features –
- PyTorch can be used as a replacement for NumPy with GPU support
- A Deep Learning platform with highest flexibility and speed
- Dynamic construction on Neural Networks
Building Neural Networks Dynamically –
All along, we have been implementing the AI models in a static way, i.e. the model is constructed with attributes of the data incorporated into it. Therefore, once a model is built, it can only be reused. Changing the behavior of the network requires a complete rebuilding of the model from scratch. This is how the popular ML frameworks like TensorFlow, Theano, Caffe, CNTK work.
But there has been a growing interest in constructing neural networks dynamically. i.e. during the runtime. It should not be confused with Dynamic Neural Networks. PyTorch and few other frameworks like DyNet offer this feature. Of course, building Dynamic Neural Networks like Recursive Neural Networks becomes much easier in these frameworks. Constructing NNs dynamically offers a good advantage. One can use an instance of a network for learning a particular structure of the input and deploy multiple such instances to form a complete model.
For example, in Natural Language Processing, the question “What is the color of the object right of the cat?” has so many levels of understanding – identifying the cat, moving right, identifying the color of that object. Different questions have varying levels and a Network built dynamically would be the most appropriate for such a task. The following image shows how the question “Is there a red object above a circle?” is understood at different levels and is answered.
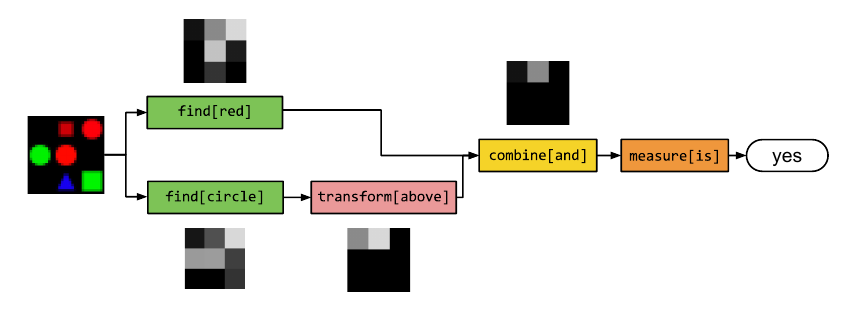
PyTorch dynamically builds the network using a technique called Reverse-Mode Auto-Differentiation, but it is beyond the scope of this post. The supremacy of PyTorch is that it performs the optimization tasks faster and makes the models maximally memory efficient compared to other ML libraries providing the same features.

The Dynamic view of Neural Networks is the future. By being one of the first ML frameworks to bring in this feature, PyTorch would surely make a lot of researchers shift to it. What are your thoughts about Dynamic Neural Networks? Give PyTorch a try and share your experience with us.
You might want to add something, drop your thoughts in the comments.
Comments
Post a Comment